
TL;DR
- India’s AI datacenter market surges at 35.1% CAGR to $3.55B by 2030, demanding token-efficient LLMs for edge AI infrastructure and RackBank GigaCampus scalability.
- LLM fine-tuning via quantization, pruning, and token compression cuts inference costs 30-50% while enabling low-latency edge deployments.
- Edge-to-core AI architecture unifies GPU datacenter for LLMs with hyperscale RackBank GigaCampus, powering enterprise AI workloads India-wide.
- Token-efficient LLMs reduce token costs for distributed AI infrastructure, scaling from edge inference to multi-node LLM training.
As CTO at RackBank, I’ve watched India’s AI datacenter landscape explode. The AI infrastructure sector is experiencing rapid expansion, driven by soaring demand for GPU-powered solutions and edge AI capabilities that optimize large language model operations, fueled by GPU datacenters for LLMs demand. Enterprises face exploding LLM token costs, yet edge AI infrastructure and RackBank GigaCampus offer the fix through LLM fine-tuning and LLM token optimization.
Here’s what I’m seeing: raw LLMs guzzle tokens, crippling low-latency AI inference at edge. But token-efficient LLMs change that. We’ve deployed these in hybrid setups, slashing costs while boosting performance across edge-to-core AI architecture. This isn’t theory, it’s RackBank’s playbook for AI GigaCampus integration.
LLM Inference Optimization: Core Techniques
Efficient Model Fine-Tuning for Token Efficiency
LLM fine-tuning starts with data composition scaling laws: volume (examples × token length) predicts performance under GPU limits. How to fine-tune LLM tokens for edge AI? Target niche tasks, extending context via positional interpolation without ballooning tokens.
At RackBank, we apply this in GPU cluster scalability tests, fine-tuning models 20-30% leaner for enterprise AI workloads India.
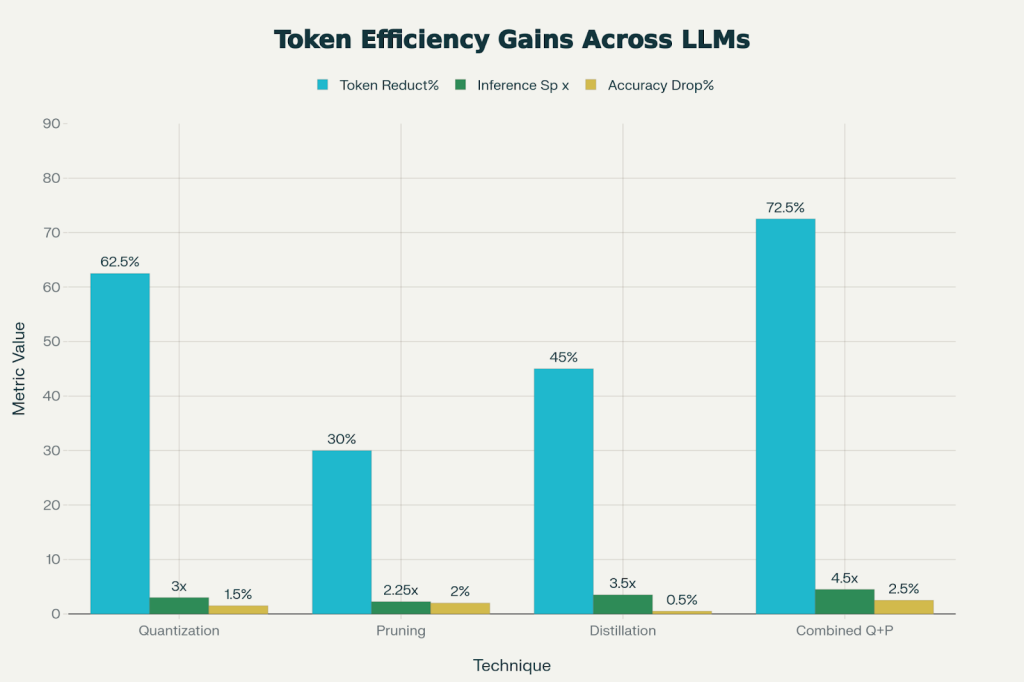
LLM Quantization & Pruning in Practice
Token compression techniques LLM like quantization drop precision (INT8 from FP16), pruning zeros redundant weights (20% sparsity typical). These yield low-latency AI inference at edge, with minimal accuracy loss.
In real-world deployments, Indian enterprises run pruned LLMs on edge nodes while offloading heavy compute to RackBank’s GigaCampus, showcasing a seamless hybrid AI architecture across edge and core.
Edge AI Deployment Meets High-Performance Compute
Edge AI infrastructure thrives on distributed AI infrastructure. RackBank’s GigaCampus ONE (50MW scalable, 100% green energy) anchors this, linking edge nodes via submarine connectivity.
Challenges? Bandwidth bottlenecks and privacy. Solutions- LLM training accelerators with token pruning strategies for scalable LLM training, enabling real-time generative AI optimization India.
India’s 80,000+ GPUs deployed underscore GPU datacenter for LLMs urgency, RackBank GigaCampus scales multi-node LLM training seamlessly.
Scaling Generative AI Optimization India
AI workload optimization demands high-performance compute clusters. RackBank GigaCampus Raipur’s 80MW roadmap and Chennai’s hyperscale powers this. Benefits of token-optimized LLMs for AI datacenters? 30-50% cost cuts, edge-to-core integration for large language models.
Best practices for deploying fine-tuned LLMs across edge regions: Start edge-local inference, burst to GigaCampus for training. This edge-to-core AI architecture handles India’s enterprise AI workloads.
FAQs
How to fine-tune LLM tokens for edge AI?
Fine-tune on domain data with positional tweaks, then quantize, deploying lean models for low-latency edge AI infrastructure.
What are the best techniques for token-efficient LLM inference?
Quantization and pruning tops the list, compressing tokens 60%, while hitting 3x speedups on GPU clusters.
How can enterprises reduce LLM token costs for large-scale AI workloads?
Token pruning strategies for scalable LLM training cut volume 40%, ideal for India’s GPU datacenter for LLMs.
What is the most effective way to fine-tune LLMs for low-latency edge deployments?
Prioritize distillation post-fine-tuning; test on edge hardware for seamless edge AI deployment.
How can organizations scale generative AI across Edge, Core, and GigaCampus architectures?
Layered LLM token-compression in RackBank’s distributed AI infrastructure boosts scalability by reducing compute load, optimizing bandwidth, and enabling seamless Edge-to-GigaCampus coordination
