
TL;DR:
- Real-time workloads such as AI inference, autonomous systems, fintech transactions, and industrial IoT demand sub-millisecond response times that shared cloud infrastructure consistently fails to deliver.
- Dedicated servers solve three problems at once for edge deployments: noisy-neighbor variability, unpredictable network paths, and the compute headroom required for GPU and accelerator workloads close to the data source.
- Bare metal at the edge is no longer about raw price-performance alone. It is about deterministic latency, hardware-level isolation for compliance, and the ability to pin specific accelerators to specific workloads.
- For India-first, globally distributed deployments, proximity to data, carrier-neutral peering, and operator-grade SLAs matter as much as the CPU SKU you choose.
- RackBank’s dedicated server ecosystem is built for this shift, with high-performance bare metal, GPU options, and edge-ready deployment patterns for enterprises building real-time products.
Introduction: The Rise of Edge and Real-Time Applications
A decade ago, “real-time” meant a few hundred milliseconds. Today, an autonomous forklift on a warehouse floor, a UPI transaction at peak hour, or a multiplayer game session expects answers in tens of milliseconds, sometimes less. The user is no longer patient, and the application is no longer allowed to be.
This shift is what is driving edge computing from a buzzword into actual line items on infrastructure budgets. Workloads are moving out of centralized hyperscale regions and toward the user, the sensor, the camera, the trading engine. And the compute layer that sits underneath all of this is being rebuilt around one question: how do we get predictable performance, every time, at the edge?
Dedicated servers are quietly becoming the answer.
Why Traditional Infrastructure Struggles with Real-Time Workloads
Shared cloud instances were designed for elasticity, not determinism. That distinction matters more than it sounds.
When a virtual machine runs on a hypervisor alongside dozens of other tenants, three things happen that hurt real-time workloads:
- Noisy neighbors. A spike in someone else’s workload can steal CPU cycles, cache lines, or memory bandwidth from yours.
- Network path variability. Multi-tenant overlay networks add jitter that is invisible on a dashboard but very visible to a trading algorithm or an inference pipeline.
- Cold-start unpredictability. Serverless and burst-capable instances often pay a startup tax that is unacceptable for sub-100ms SLAs.
For analytics dashboards or batch jobs, none of this matters. For an AI inference endpoint feeding a fraud-detection model at 2,000 requests per second, all of it matters.
What Makes Dedicated Servers Ideal for Edge Computing
Dedicated servers, also called bare metal, give you the whole machine. No hypervisor between your workload and the silicon. No other tenants. That single architectural choice unlocks several properties that edge computing genuinely needs:
| Property | What it means in practice |
|---|---|
| Deterministic performance | The p99 latency looks like the p50 latency, because nothing else is fighting for the CPU |
| Hardware-level isolation | Easier compliance posture for PCI DSS, HIPAA, RBI guidelines, and similar frameworks |
| Direct hardware access | NICs, GPUs, NVMe, and FPGAs perform at their actual datasheet numbers |
| Predictable cost at scale | Sustained workloads cost less than the equivalent reserved cloud capacity |
| Customizable network paths | Carrier-neutral peering and BGP control closer to the user |
For an edge deployment, those properties stop being nice-to-have and start being the actual reason the architecture works.
Low Latency Infrastructure for Real-Time Processing
Latency is a stack, not a number. You can break it down roughly like this:
- Geographic latency: the speed of light over the distance between user and server
- Network latency: routing hops, queueing, peering choices
- Compute latency: time spent in the OS, hypervisor, and application
- Storage latency: disk and memory access patterns
The Impact in Real-Time Applications:
A centralized cloud deployment in Mumbai serving a user in Indore might add 25 to 40 ms just on the first two. Move the compute to a regional edge node, run it on dedicated hardware, and that number can drop below 10 ms. For a video game, that is the difference between playable and unplayable. For a robotic arm, it is the difference between safe and unsafe.
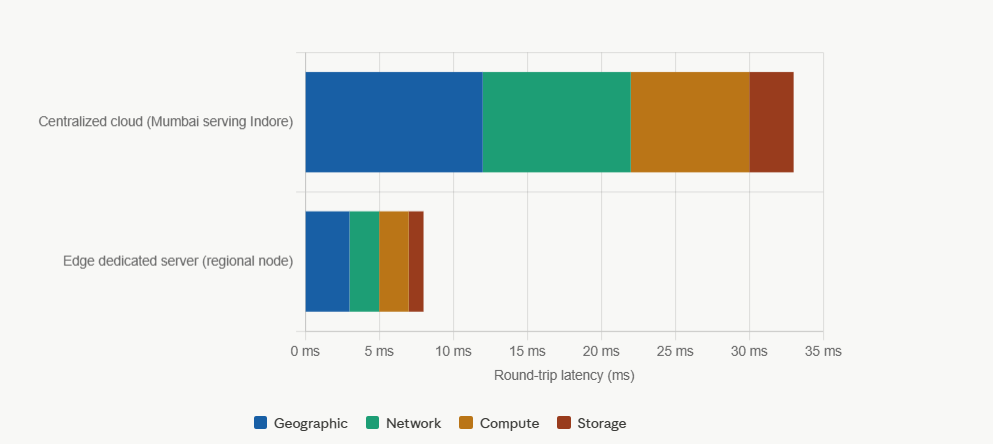
Dedicated Servers vs Cloud Instances for Edge Deployments
Both have a place. The honest comparison looks like this:
| Dimension | Dedicated Servers | Public Cloud Instances |
|---|---|---|
| Latency consistency | Excellent, hardware-pinned | Variable, depends on tenant mix |
| Cost at sustained load | Lower, especially at 24/7 utilization | Higher beyond a usage threshold |
| Elasticity for spiky traffic | Limited unless paired with autoscaling | Excellent |
| GPU and accelerator access | Full, dedicated | Often shared or virtualized |
| Compliance and data residency | Strong, location-fixed | Strong but with shared-responsibility nuances |
| Time to provision | Hours to a day | Minutes |
Edge and real-time workloads tend to be sustained, latency-sensitive, and compliance-bound. That maps almost perfectly to the strengths of dedicated infrastructure.
Role of Dedicated Servers in AI and Edge AI Applications
Edge AI is where this conversation gets sharpest. Training happens in centralized clusters. Inference, increasingly, does not.
When a model needs to classify a security camera frame, route a delivery drone, or score a credit transaction in 20 ms, the inference path cannot include a round-trip to a distant data center. The model needs to run on a GPU or accelerator sitting close to the data source. Dedicated GPU servers give you that, with full control over the accelerator, the memory, and the I/O path.
This matters for cost too. Shared GPU instances often charge for full cards while giving partial access. A dedicated GPU server gives the entire device, with no virtualization tax on tensor throughput.
Real-Time Use Cases Powered by Dedicated Servers
Autonomous Systems
Self-driving features, warehouse robots, and drone fleets need decisions in single-digit milliseconds. The compute supporting them must run on hardware that does not stutter.
Smart Cities
Traffic optimization, public safety video analytics, and grid management ingest thousands of streams. Centralized processing is too slow. Distributed dedicated nodes process at the source and forward only what matters.
Industrial IoT
A modern factory floor generates terabytes per day from vibration sensors, vision systems, and PLCs. Anomaly detection has to happen locally, on dedicated infrastructure, before that data ever crosses the WAN.
FinTech Transactions
UPI, card networks, and real-time settlement systems live and die by p99 latency. Dedicated infrastructure with predictable performance and audited isolation is effectively the baseline.
Video Streaming and Gaming
Game servers, live-streaming origin nodes, and low-latency CDN POPs run best on bare metal where bandwidth and frame timing are controllable end-to-end.
AI Inference at the Edge
Computer vision, language models tuned for specific domains, recommendation engines responding to live behavior. All of them benefit from dedicated GPU servers placed close to where the queries originate.
Importance of Bare Metal Performance for Edge Workloads
Bare metal is not romantic. It is just honest. You ask the hardware to do something, and the hardware does it, without a hypervisor translating, scheduling, or throttling on the way.
For edge workloads, that honesty shows up as:
- Higher and more stable packet-per-second rates on the NIC
- Lower and tighter inference latency on GPUs
- Predictable NVMe throughput for high-write workloads
- Cleaner thermal and power profiles, which matter at constrained edge sites
These are not theoretical wins. They show up in production dashboards, in SLA reports, and in customer experience metrics.
Network Optimization and Data Proximity in Edge Infrastructure
A dedicated server in the wrong location is still a slow server. Edge infrastructure has to combine three things to actually deliver on its promise:
- Geographic placement close to users or data sources
- Carrier-neutral connectivity with diverse upstream paths
- Direct peering with major networks and ISPs to cut hops
This is where data center selection matters as much as the server itself. A bare metal box plugged into a well-peered, regionally placed facility outperforms a faster box in a poorly connected one.
Scalability and Reliability for Mission-Critical Applications
Scalability at the edge looks different from scalability in the cloud. You are not just adding more VMs. You are adding more sites, more locations, more hardware footprints, each of which needs to be operated like a small data center.
This calls for:
- Standardized server configurations that can be replicated quickly
- Out-of-band management for remote operations
- Redundant power, network, and cooling at each site
- Automated provisioning and lifecycle management
When done well, a dedicated server fleet across multiple edge locations delivers higher availability than a single centralized cloud region, simply because the failure of any one site does not take the whole service down.
Security and Compliance Benefits of Dedicated Infrastructure
Single-tenant hardware is a meaningful security boundary. There is no other workload on the same physical machine, no shared cache to side-channel, no hypervisor escape to worry about.
For regulated industries, including banking, healthcare, public sector, and increasingly AI applications handling personal data, this matters. Indian regulations around data localization, RBI guidelines on payment data, and global frameworks like GDPR all become easier to address when the underlying hardware is dedicated and the physical location is known and controlled.
How RackBank Supports Edge and Real-Time Deployments
RackBank operates Tier III and Tier IV datacenter infrastructure in India with a focus on dedicated server and GPU server deployments built for performance-sensitive workloads. The platform supports:
- High-performance bare metal servers across multiple CPU generations
- GPU dedicated servers for AI training and edge inference
- Carrier-neutral connectivity with strong peering
- Compliance-ready facilities for regulated workloads
- Custom configurations for specific edge and real-time use cases
For teams building India-first, globally ready products, the combination of local presence, dedicated hardware, and operator-grade reliability removes a lot of the engineering work that would otherwise go into making cloud-native infrastructure behave deterministically.
Future of Edge Computing and Dedicated Server Infrastructure
Three trends are converging. AI inference is decentralizing. Networks are getting faster but propagation delay is not changing. And regulators are getting more specific about where data must live and how it must be processed.
The infrastructure pattern that comes out of this convergence is straightforward. Distributed edge sites, each running dedicated servers with the right mix of CPU and GPU, connected by well-peered networks, operated under enterprise SLAs. Less centralized, more deterministic, closer to the workload.
Bare metal is not making a comeback. It never really left the workloads that actually needed it. What is changing is that more workloads now need it.
Conclusion
Edge and real-time applications are not a niche category anymore. They are most of what gets built in AI, fintech, gaming, industrial automation, and consumer products that respond instantly. The infrastructure underneath them needs to match that profile, with predictable latency, hardware isolation, and the right accelerators placed in the right locations.
Dedicated servers are not a nostalgic choice. They are the practical foundation for the next generation of latency-sensitive workloads, and the gap between what shared cloud delivers and what these workloads actually need is only widening.
If you are building something where p99 latency, uptime, and compliance are non-negotiable, RackBank’s dedicated server and GPU server platforms are worth a closer look.
Talk to RackBank about your edge or real-time workload and get bare metal servers tailored to your performance requirements.


