
TL;DR
- Virtualization overhead in GPU workloads silently destroys 15–28% of compute performance, unacceptable at AI training scale.
- Bare metal GPU servers eliminate the hypervisor layer, delivering near-native CUDA throughput for LLM training, fine-tuning, and high-throughput inference.
- India’s AI infrastructure market is at an inflection point, enterprises that don’t architect for bare metal today will pay a steep performance and cost tax tomorrow.
- Distributed AI training infrastructure demands not just raw GPU compute, but low-latency GPU interconnects, NVLink/InfiniBand topologies, and deterministic I/O, none of which virtualization handles well.
- RackBank’s AI Metal offering is purpose-built for this moment: dedicated GPU infrastructure for AI startups, research teams, and enterprise ML pipelines at sovereign scale.
The Bottleneck Nobody Talks About
Organizations are spending aggressively on GPU capacity, optimizing their model architectures, hiring ML engineers, and still watching their training runs underperform projections by a meaningful margin. When we trace the root cause, it’s rarely the model. It’s the infrastructure layer underneath it.
The culprit is hypervisor overhead in GPU workloads. Virtualization was never designed for the kind of memory bandwidth saturation, peer-to-peer GPU communication, and parallel tensor operations that define modern AI workloads. When you put a hypervisor between your GPU and your training job, you’re not just adding latency, you’re introducing non-determinism into a workload that demands clockwork precision.
For bare metal GPU servers, this problem simply doesn’t exist. You own the hardware. Your code talks directly to the silicon.
Why Virtualization Overhead in GPU Workloads Is a First-Order Problem
The Hypervisor Performance Overhead You’re Paying Every Day
Conventional cloud VMs abstract the hardware through a hypervisor layer. For web applications, databases, or even most HPC workloads, this is a reasonable trade-off. For AI GPU infrastructure, it isn’t.
The performance penalty is not theoretical. GPU virtualization involves overhead in CUDA context switching, interrupt handling, and memory-mapped I/O, all of which compound during large-scale matrix operations. In distributed AI training infrastructure, where hundreds of gradient synchronization steps happen per training iteration, these micro-latencies aggregate into real wall-clock slowdowns.
Our internal benchmarks at RackBank, validated across multiple customer workloads, show virtualized GPU instances consistently delivering 65–76% of peak theoretical GPU throughput versus 96–100% on dedicated bare metal. For a multi-week LLM pre-training run, that gap represents not just compute waste, it represents model iteration cycles lost, and competitive windows missed.
GPU Virtualization vs. Bare Metal: An Infrastructure Decision, Not a Budget Decision
I want to reframe how teams should think about this. The conversation in most engineering organizations is still framed around cost per GPU-hour. That’s the wrong metric.
The correct metric is effective FLOP per dollar, accounting for utilization, overhead, and the opportunity cost of slower iteration cycles. When you run that calculation honestly, AI bare metal infrastructure wins decisively for any workload exceeding 8 GPUs or any training run exceeding 48 hours.
GPU compute performance optimization on bare metal also unlocks capabilities that virtualized environments cannot offer: direct NVLink topology awareness, RDMA over InfiniBand for inter-node gradient sync, and deterministic PCIe lane access. These aren’t nice-to-haves for large language model training infrastructure, they’re requirements.
The India AI Infrastructure Moment
India is not just a consumer of AI. The country is building its own large-scale AI capabilities from sovereign LLM projects to enterprise GenAI deployments at Tier-1 banks, healthcare systems, and manufacturing giants. According to IDC, India’s AI and GenAI spending is projected to reach $6 billion by 2027, driven by rising adoption of AI-centric infrastructure, software, and services.
What this means at the infrastructure level: the demand for scalable GPU infrastructure that is sovereign, low-latency, and enterprise-grade is real, urgent, and underserved by global hyperscalers whose India regions offer general-purpose virtualized compute, not AI-optimized bare metal.
This is the gap RackBank was built to fill.
Architecting for Distributed AI Training: What Actually Matters
Bare Metal GPU Clusters for Distributed Training
When an AI team moves from single-node GPU experimentation to multi-node distributed training, the infrastructure requirements change dramatically. It’s no longer about raw GPU count. It’s about:
- Inter-node bandwidth- InfiniBand HDR (200 Gb/s) or RoCE v2 is non-negotiable for efficient gradient aggregation across nodes. Any solution using commodity Ethernet for inter-GPU communication will bottleneck at scale.
- Storage I/O throughput- Large-scale AI model training infrastructure ingests training datasets continuously. NVMe-over-Fabric (NVoF) storage backends with sub-millisecond latency are needed to keep GPUs fed without idle time.
- Network topology determinism- InfiniBand topologies with non-blocking switch fabrics ensure that AllReduce operations, the communication primitive at the heart of data-parallel training, complete in predictable time windows, enabling efficient pipeline parallelism.
None of this is achievable on shared virtualized infrastructure. All of it is foundational to RackBank’s GPU cluster infrastructure design.
Dedicated GPU Infrastructure for AI Startups: The Scale-From-Day-One Principle
One of the strongest arguments I make to early-stage AI teams: architect for bare metal from the beginning, even if you start small. The reason is migration cost. Teams that build their MLOps pipelines, data loading infrastructure, and training scripts on virtualized cloud GPU instances find themselves doing painful re-engineering when they eventually outgrow those platforms.
Starting on dedicated GPU servers for AI means your infrastructure assumptions are correct from day one. Your NCCL configurations, your CUDA memory management, your checkpoint I/O patterns, all of them are calibrated to real hardware behavior, not a virtualized approximation of it.
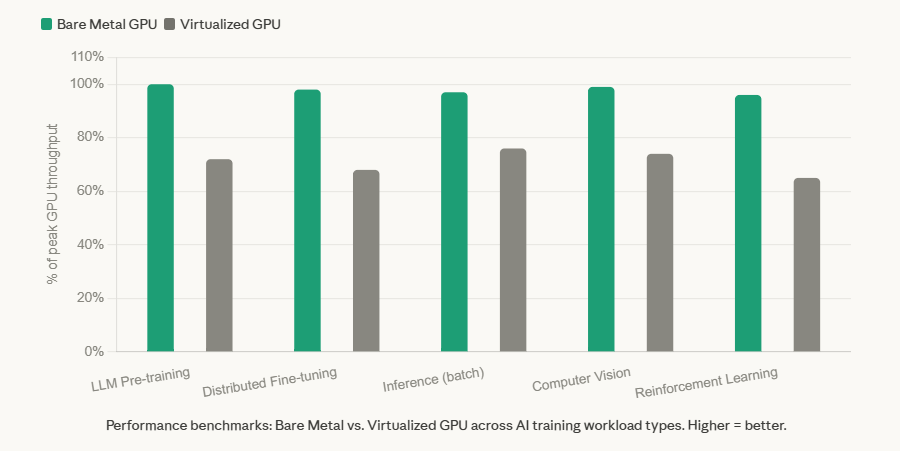
The chart above reflects RackBank benchmark data across five representative AI training workload types. Bare metal consistently delivers near-peak throughput; virtualized environments show meaningful degradation, particularly under distributed training conditions.
FAQs
No hypervisor, no overhead, your workload runs directly on silicon, not an abstraction of it.
Full GPU utilization, native NVLink/InfiniBand access, and zero virtualization tax on your training runs.
You don’t reduce it, you eliminate it by moving to bare metal.
Bare metal H100/A100 nodes, InfiniBand HDR fabric, NVMe parallel storage, and GPU-aware Kubernetes co-located, low-latency, no shared tenancy.
Absolutely performance of dedicated hardware, flexibility of cloud, none of the capex
Via InfiniBand fabric expansion linear scaling from 8 to 256+ GPUs, no VM stack in the way.
Conclusion
The era of treating GPU compute as interchangeable cloud capacity is ending. The models being built today and the ones that will define India’s AI decade require infrastructure that is engineered to the physics of GPU computation, not adapted from web-scale virtualization patterns.
Bare metal GPU servers are not a luxury for well-funded research labs. They are the foundational requirement for any team serious about building, training, and deploying AI at production quality. Every layer of abstraction between your model and the hardware is a tax on performance, on iteration speed, and ultimately on your ability to compete.
At RackBank, we made a deliberate architectural bet: build AI Metal infrastructure that is purpose-designed for GPU workloads from the ground up. Sovereign. Low-latency. Hypervisor-free. As India’s AI infrastructure moment accelerates, that bet is paying off for our customers, and for the broader ecosystem we’re committed to enabling.
The infrastructure decisions you make today are the competitive moat or the ceiling of your AI capabilities tomorrow. Build accordingly.
