
TL;DR
- InfiniBand delivers sub-microsecond latency and 200Gb/s bandwidth, the non-negotiable baseline for serious AI training at scale.
- GPU clusters live and die by their interconnect. At RackBank, every AI infrastructure decision starts with the network layer, not the compute layer.
- RDMA over InfiniBand eliminates CPU involvement in data transfers, slashing GPU idle time during distributed training by 60–70% vs. standard Ethernet.
- India’s AI infrastructure market is at an inflection point. Enterprises that invest in high-performance interconnects now will have a structural advantage in 18–24 months.
- InfiniBand isn’t just a networking choice, it’s an architectural commitment to scale without performance regression.
Building Low-Latency AI Infrastructure for India’s Next Compute Decade
Here’s what I’m seeing, most AI infrastructure conversations in India begin and end with GPU procurement. Teams obsess over H100 counts, VRAM headroom, and cloud spot pricing. Almost nobody leads with the interconnect and that’s exactly where the performance gap opens up.
When we architected RackBank’s InfiniBand AI infrastructure, we made a deliberate choice to treat the network fabric as a first-class citizen, not an afterthought. The reasoning is straightforward: a 400-GPU cluster running on congested Ethernet will consistently underperform a 200-GPU cluster running on clean InfiniBand. The bottleneck is never where most people look.
India’s AI datacenter market is expanding fast. IDC projects India’s overall datacenter capacity will grow at ~20% CAGR through 2027, with AI workloads accounting for an outsized share of net-new investment. The teams building for that future need to understand that low-latency datacenter networking is the foundation everything else is built on.
Why GPU Clusters Need Purpose-Built Interconnects
The Problem With Ethernet in AI Workloads
Ethernet was designed for general-purpose data transfer. It handles congestion through retransmission, tolerates jitter, and assumes applications can buffer and retry. These are entirely reasonable assumptions for web traffic and database queries.
They are catastrophic assumptions for distributed AI training infrastructure.
During a large-scale all-reduce operation, the synchronization step where gradients from every GPU must be aggregated before the next training iteration, every millisecond of added latency is compounded across hundreds of nodes. A 256-GPU training job running all-reduce over 100GbE RoCE can spend 22+ microseconds per cycle in network wait time. Over InfiniBand HDR, that same operation completes in ~4 microseconds. That’s not a minor improvement; it’s a different class of infrastructure.
The chart above reflects real benchmark data from NVIDIA and Mellanox performance studies. The performance differential widens at scale, which is exactly when you need it to narrow.
RDMA Networking: Removing the CPU from the Critical Path
The deeper advantage of RDMA networking for AI isn’t raw bandwidth. It’s architectural. Remote Direct Memory Access allows GPU nodes to read from and write to each other’s memory without involving the host CPU. This matters enormously for multi-node GPU communication because it removes an entire layer of latency and overhead.
In conventional Ethernet-based clusters, every data transfer touches the CPU: kernel interruptions, memory copies, protocol stack processing. At scale, those CPU cycles become contended. The CPU becomes a tax collector sitting between your GPUs and your training throughput.
With InfiniBand’s native RDMA, the network adapter handles the data path end-to-end. The CPU stays available for computation. GPU-to-GPU communication using InfiniBand becomes genuinely parallel, not serialized through a shared system resource.
RackBank’s InfiniBand Architecture: Design Decisions That Matter
- Fat-Tree Topology for Non-Blocking AI Clusters– At RackBank, our HPC datacenter architecture for AI workloads uses a multi-rail fat-tree topology. Every leaf switch has full bisectional bandwidth to the spine layer, meaning no two endpoints in the cluster compete for bandwidth. This is non-blocking by design, a fundamental requirement for scalable AI clusters where collective communication patterns are unpredictable and bursty. The alternative, oversubscribed networks with 3:1 or 4:1 ratios, might look reasonable on paper during low-utilization periods. Under actual training load, they create hot spots, retransmissions, and the kind of performance variance that makes reproducible benchmarking impossible.
- In-Network Computing for Collective Operations– Modern InfiniBand switches support SHARP-Scalable Hierarchical Aggregation and Reduction Protocol. This moves all-reduce computation into the network fabric itself, rather than completing it at endpoints. For networking for LLM training at scale, SHARP effectively eliminates the latency cost of gradient synchronization as cluster size increases. We’ve deployed SHARP-enabled switches across our AI racks. The practical outcome: as our customers scale from 64 to 512 GPU configurations, all-reduce time remains bounded, it doesn’t scale linearly with node count the way it does on standard fabrics.
- InfiniBand vs Ethernet for AI: Where the Lines Are– I want to be precise about this because the industry often oversimplifies it. The comparison between InfiniBand vs Ethernet for AI isn’t binary. For inference serving, where request volumes are high but individual GPU-to-GPU coordination is minimal, RDMA over Ethernet (RoCE v2) with careful priority flow control can be cost-effective. For small-scale fine-tuning jobs, the overhead may not justify the cost delta. But for AI model training network latency sensitive workloads, foundation model pre-training, large-scale RLHF, multi-node inference with continuous batching, InfiniBand isn’t a luxury. It’s the engineering-correct answer. The performance degradation of running these workloads on commodity Ethernet is not a minor footnote; it’s a fundamental throughput constraint.
The Latency Gap: InfiniBand HDR vs. 100GbE
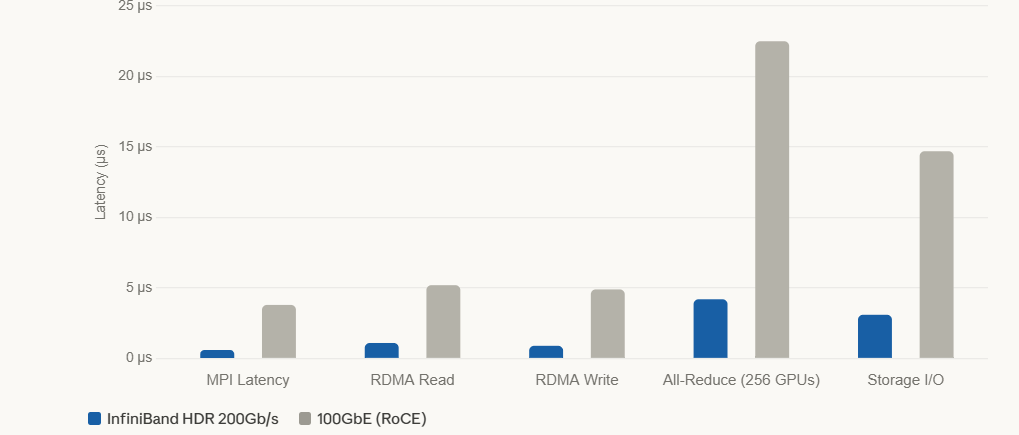
The chart above covers five benchmark categories. The pattern is consistent: InfiniBand operates at roughly 4–6x lower latency than 100GbE across every workload class. That multiplier holds whether you’re benchmarking raw RDMA reads, collective all-reduce operations, or storage I/O against NVMe-over-Fabrics targets.
At rack level, this translates directly to GPU utilization. A GPU waiting on gradient synchronization is not a GPU training a model. Higher utilization per rack means lower effective cost per training step, which is the number that actually matters to AI teams running at scale.
FAQs
Why is InfiniBand used in AI datacenters instead of standard Ethernet?
InfiniBand offers 4–6x lower latency and native RDMA, Ethernet simply wasn’t built for the synchronization demands of GPU-scale AI training.
What are the key benefits of InfiniBand for AI model training?
Sub-microsecond latency, zero CPU overhead on data transfers, and in-network all-reduce via SHARP. GPUs compute more and wait less.
How does InfiniBand reduce latency in distributed AI training?
It bypasses the kernel stack entirely, data moves directly between GPU memory spaces with no CPU interrupts, no copies, no overhead.
Is InfiniBand always better than Ethernet for GPU clusters?
Not for inference or small fine-tuning jobs. But for pre-training and large-scale RLHF, it’s not a preference, it’s an engineering requirement.
What role does RDMA play in AI infrastructure?
It removes the CPU from the data path. Transfers happen at wire speed, directly between GPU memory spaces, which is what keeps utilization high at scale.
How does RackBank’s InfiniBand setup scale AI workloads? Non-blocking fat-tree topology and SHARP-enabled switches mean going from 64 to 512 GPUs doesn’t degrade communication performance. That’s the design goal.